
Basic Tutorial#
Note
This page uses two different syntax variants:
Cython specific
cdefsyntax, which was designed to make type declarations concise and easily readable from a C/C++ perspective.Pure Python syntax which allows static Cython type declarations in pure Python code, following PEP-484 type hints and PEP 526 variable annotations.
To make use of C data types in Python syntax, you need to import the special
cythonmodule in the Python module that you want to compile, e.g.import cython
If you use the pure Python syntax we strongly recommend you use a recent Cython 3 release, since significant improvements have been made here compared to the 0.29.x releases.
The Basics of Cython#
The fundamental nature of Cython can be summed up as follows: Cython is Python with C data types.
Cython is Python: Almost any piece of Python code is also valid Cython code. (There are a few Limitations, but this approximation will serve for now.) The Cython compiler will convert it into C code which makes equivalent calls to the Python/C API.
But Cython is much more than that, because parameters and variables can be declared to have C data types. Code which manipulates Python values and C values can be freely intermixed, with conversions occurring automatically wherever possible. Reference count maintenance and error checking of Python operations is also automatic, and the full power of Python’s exception handling facilities, including the try-except and try-finally statements, is available to you – even in the midst of manipulating C data.
Cython Hello World#
As Cython can accept almost any valid python source file, one of the hardest things in getting started is just figuring out how to compile your extension.
So lets start with the canonical python hello world:
print("Hello World")
Save this code in a file named helloworld.py. Now we need to create
the setup.py, which is like a python Makefile (for more information
see Source Files and Compilation). Your setup.py should look like:
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("helloworld.py")
)
To use this to build your Cython file use the commandline options:
$ python setup.py build_ext --inplace
Which will leave a file in your local directory called helloworld.so in unix
or helloworld.pyd in Windows. Now to use this file: start the python
interpreter and simply import it as if it was a regular python module:
>>> import helloworld
Hello World
Congratulations! You now know how to build a Cython extension. But so far this example doesn’t really give a feeling why one would ever want to use Cython, so lets create a more realistic example.
Fibonacci Fun#
From the official Python tutorial a simple fibonacci function is defined as:
def fib(n):
"""Print the Fibonacci series up to n."""
a, b = 0, 1
while b < n:
print(b, end=' ')
a, b = b, a + b
print()
Now following the steps for the Hello World example we first save this code
to a Python file, let’s say fibonacci.py. Next, we create the
setup.py file. Using the file created for the Hello World example, all
that you need to change is the name of the Cython filename, and the resulting
module name, doing this we have:
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules=cythonize("fibonacci.py"),
)
Build the extension with the same command used for the “helloworld.py”:
$ python setup.py build_ext --inplace
And use the new extension with:
>>> import fibonacci
>>> fibonacci.fib(2000)
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597
Primes#
Here’s a small example showing some of what can be done. It’s a routine for finding prime numbers. You tell it how many primes you want, and it returns them as a Python list.
1def primes(nb_primes: cython.int):
2 i: cython.int
3 p: cython.int[1000]
4
5 if nb_primes > 1000:
6 nb_primes = 1000
7
8 if not cython.compiled: # Only if regular Python is running
9 p = [0] * 1000 # Make p work almost like a C array
10
11 len_p: cython.int = 0 # The current number of elements in p.
12 n: cython.int = 2
13 while len_p < nb_primes:
14 # Is n prime?
15 for i in p[:len_p]:
16 if n % i == 0:
17 break
18
19 # If no break occurred in the loop, we have a prime.
20 else:
21 p[len_p] = n
22 len_p += 1
23 n += 1
24
25 # Let's copy the result into a Python list:
26 result_as_list = [prime for prime in p[:len_p]]
27 return result_as_list
1def primes(int nb_primes):
2 cdef int n, i, len_p
3 cdef int[1000] p
4
5 if nb_primes > 1000:
6 nb_primes = 1000
7
8
9
10
11 len_p = 0 # The current number of elements in p.
12 n = 2
13 while len_p < nb_primes:
14 # Is n prime?
15 for i in p[:len_p]:
16 if n % i == 0:
17 break
18
19 # If no break occurred in the loop, we have a prime.
20 else:
21 p[len_p] = n
22 len_p += 1
23 n += 1
24
25 # Let's copy the result into a Python list:
26 result_as_list = [prime for prime in p[:len_p]]
27 return result_as_list
The two syntax variants (“Pure Python” and “Cython”) represent different ways of annotating the code with C data types. The first uses regular Python syntax with Cython specific type hints, thus allowing the code to run as a normal Python module. Python type checkers will ignore most of the type details, but on compilation, Cython interprets them as C data types and uses them to generate tightly adapted C code.
The second variant uses a Cython specific syntax. This syntax is mostly used
in older code bases and in Cython modules that need to make use of advanced
C or C++ features when interacting with C/C++ libraries. The additions to
the syntax require a different file format, thus the .pyx extension:
Python code ‘extended’.
For this tutorial, assuming you have a Python programming background, it’s probably best to stick to the Python syntax examples and glimpse at the Cython specific syntax for comparison.
You can see that the example above starts out just like a normal Python function
definition, except that the parameter nb_primes is declared to be of Cython
type int (not the Python type of the same name). This means that the Python
object passed into the function will be converted to a C integer on entry,
or a TypeError will be raised if it cannot be converted.
Now, let’s dig into the core of the function:
2i: cython.int
3p: cython.int[1000]
11len_p: cython.int = 0 # The current number of elements in p.
12n: cython.int = 2
Lines 2, 3, 11 and 12 use the variable annotations
to define some local C variables.
The result is stored in the C array p during processing,
and will be copied into a Python list at the end (line 26).
2cdef int n, i, len_p
3cdef int[1000] p
Lines 2 and 3 use the cdef statement to define some local C variables.
The result is stored in the C array p during processing,
and will be copied into a Python list at the end (line 26).
Note
You cannot create very large arrays in this manner, because they are allocated on the C function call stack, which is a rather precious and scarce resource. To request larger arrays, or even arrays with a length only known at runtime, you can learn how to make efficient use of C memory allocation, Python arrays or NumPy arrays with Cython.
5if nb_primes > 1000:
6 nb_primes = 1000
As in C, declaring a static array requires knowing the size at compile time. We make sure the user doesn’t set a value above 1000 (or we would have a segmentation fault, just like in C)
8if not cython.compiled: # Only if regular Python is running
9 p = [0] * 1000 # Make p work almost like a C array
When we run this code from Python, we have to initialize the items in the array. This is most easily done by filling it with zeros (as seen on line 8-9). When we compile this with Cython, on the other hand, the array will behave as in C. It is allocated on the function call stack with a fixed length of 1000 items that contain arbitrary data from the last time that memory was used. We will then overwrite those items in our calculation.
10len_p: cython.int = 0 # The current number of elements in p.
11n: cython.int = 2
12while len_p < nb_primes:
10len_p = 0 # The current number of elements in p.
11n = 2
12while len_p < nb_primes:
Lines 11-13 set up a while loop which will test numbers-candidates to primes until the required number of primes has been found.
14# Is n prime?
15for i in p[:len_p]:
16 if n % i == 0:
17 break
Lines 15-16, which try to divide a candidate by all the primes found so far,
are of particular interest. Because no Python objects are referred to,
the loop is translated entirely into C code, and thus runs very fast.
You will notice the way we iterate over the p C array.
15for i in p[:len_p]:
The loop gets translated into a fast C loop and works just like iterating
over a Python list or NumPy array. If you don’t slice the C array with
[:len_p], then Cython will loop over the 1000 elements of the array.
19# If no break occurred in the loop, we have a prime.
20else:
21 p[len_p] = n
22 len_p += 1
23n += 1
If no breaks occurred, it means that we found a prime, and the block of code
after the else line 20 will be executed. We add the prime found to p.
The else clause after a for-loop is a lesser known features of the Python language
that Cython executes at C speed for you. If this syntax confuses you, the
Python documentation
presents a good way to think of the else clause:
Imagine it paired with the if inside the loop.
As the loop executes, it will run a sequence like if / if / if / else.
The if is inside the loop, encountered a number of times.
If the condition is ever true, a break will happen.
If the condition is never true, the else clause outside the loop will execute.
25# Let's copy the result into a Python list:
26result_as_list = [prime for prime in p[:len_p]]
27return result_as_list
In line 26, before returning the result, we need to copy our C array into a
Python list, because Python can’t read C arrays. Cython can automatically
convert many C types from and to Python types, as described in the
documentation on type conversion, so we can use
a simple list comprehension here to copy the C int values into a Python
list of Python int objects, which Cython creates automatically along the way.
You could also have iterated manually over the C array and used
result_as_list.append(prime), the result would have been the same.
You’ll notice we declare a Python list exactly the same way it would be in Python.
Because the variable result_as_list hasn’t been explicitly declared with a type,
it is assumed to hold a Python object, and from the assignment, Cython also knows
that the exact type is a Python list.
Finally, at line 27, a normal Python return statement returns the result list.
Compiling primes.py with the Cython compiler produces an extension module which we can try out in the interactive interpreter as follows:
Compiling primes.pyx with the Cython compiler produces an extension module which we can try out in the interactive interpreter as follows:
>>> import primes
>>> primes.primes(10)
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29]
See, it works! And if you’re curious about how much work Cython has saved you, take a look at the C code generated for this module.
Cython has a way to visualise where interaction with Python objects and
Python’s C-API is taking place. For this, pass the
annotate=True parameter to cythonize(). It produces a HTML file. Let’s see:
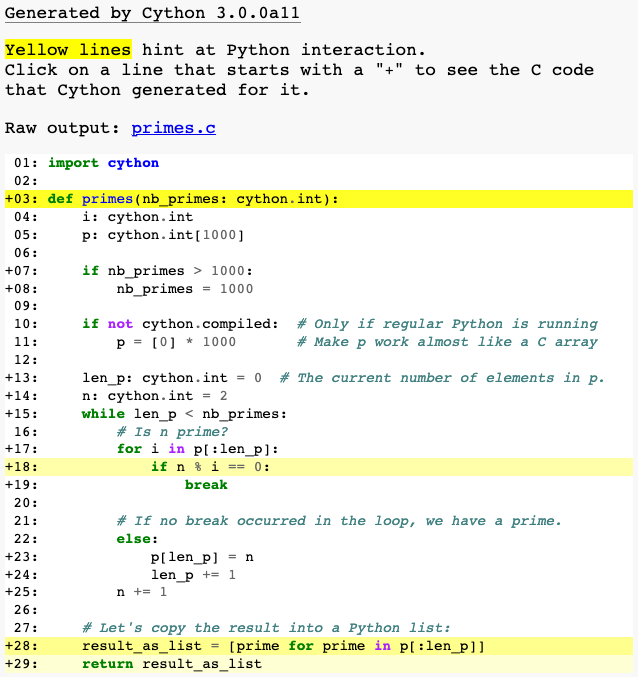
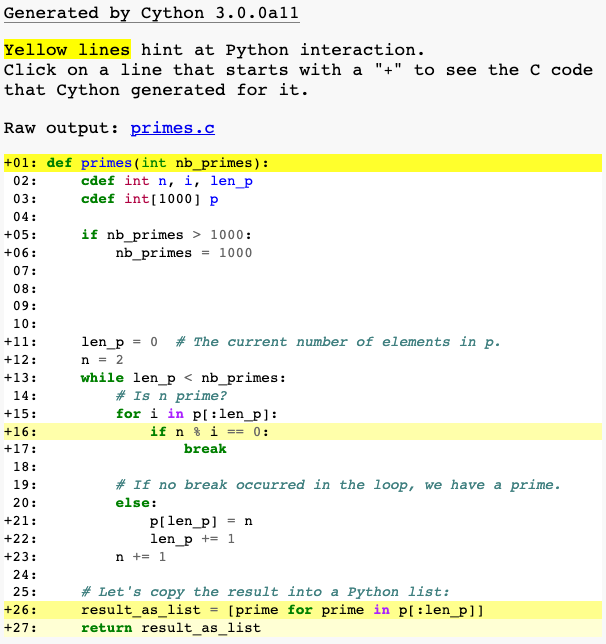
If a line is white, it means that the code generated doesn’t interact
with Python, so will run as fast as normal C code. The darker the yellow, the more
Python interaction there is in that line. Those yellow lines will usually operate
on Python objects, raise exceptions, or do other kinds of higher-level operations
than what can easily be translated into simple and fast C code.
The function declaration and return use the Python interpreter so it makes
sense for those lines to be yellow. Same for the list comprehension because
it involves the creation of a Python object. But the line if n % i == 0:, why?
We can examine the generated C code to understand:
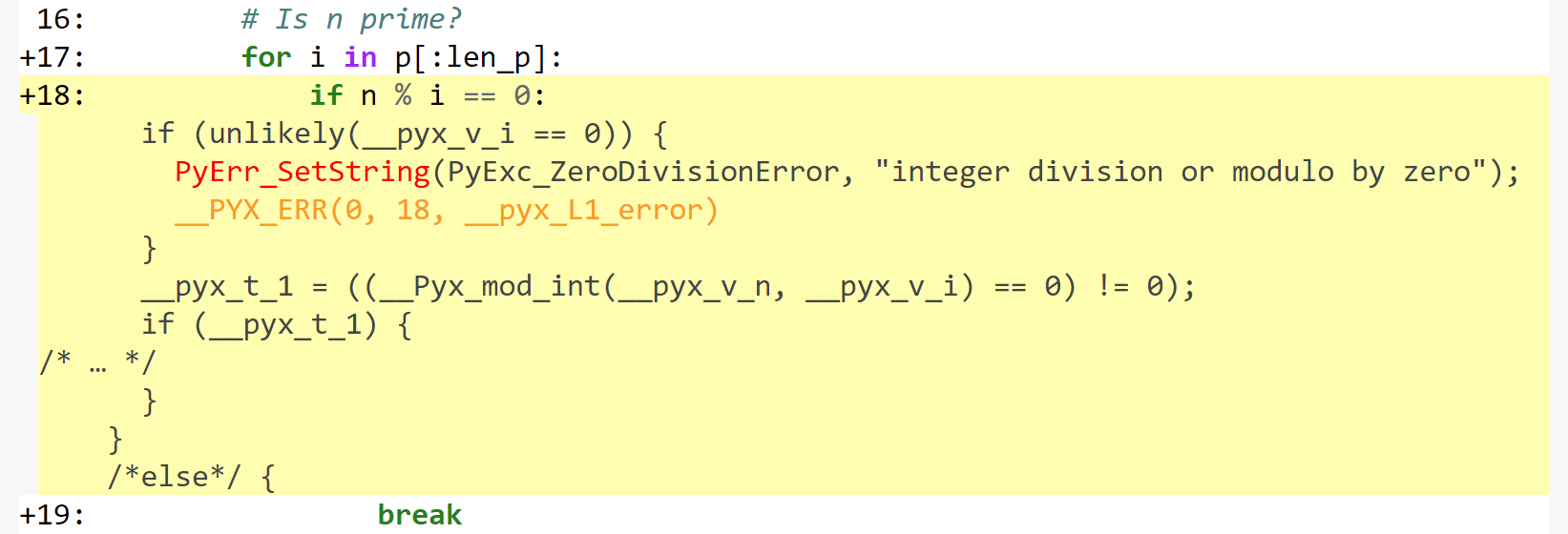
We can see that some checks happen. Because Cython defaults to the Python behavior, the language will perform division checks at runtime, just like Python does. You can deactivate those checks by using the compiler directives.
Now let’s see if we get a speed increase even if there is a division check. We can write the same program, but in simple Python, without type declarations:
def primes(nb_primes):
p = []
n = 2
while len(p) < nb_primes:
# Is n prime?
for i in p:
if n % i == 0:
break
# If no break occurred in the loop
else:
p.append(n)
n += 1
return p
Save it as primes_python.py.
For comparison, let’s create a copy of primes_python.py and name it primes_python_compiled.py.
Then we can compile that module with Cython and compare it to the (non-compiled) Python module
with the same code.
Now change the setup.py as follows, to compile both the optimised and the new plain Python code module:
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules=cythonize(
['primes.py', # Cython code file with primes() function
'primes_python_compiled.py'], # Python code file with primes() function
annotate=True), # enables generation of the html annotation file
py_modules=["primes_python.py"], # Tells setuptools to include this Python module as well
)
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules=cythonize(
['primes.pyx', # Cython code file with primes() function
'primes_python_compiled.py'], # Python code file with primes() function
annotate=True), # enables generation of the html annotation file
py_modules=["primes_python.py"], # Tells setuptools to include this Python module as well
)
Now we can ensure that the two new modules output the same values as before:
>>> import primes, primes_python, primes_python_compiled
>>> primes_python.primes(1000) == primes.primes(1000)
True
>>> primes_python_compiled.primes(1000) == primes.primes(1000)
True
Let’s compare the speed of all three modules:
python -m timeit -s "from primes_python import primes" "primes(1000)"
10 loops, best of 3: 23 msec per loop
python -m timeit -s "from primes_python_compiled import primes" "primes(1000)"
100 loops, best of 3: 11.9 msec per loop
python -m timeit -s "from primes import primes" "primes(1000)"
1000 loops, best of 3: 1.65 msec per loop
The cythonize version of primes_python is 2 times faster than the Python one,
without changing a single line of code.
The Cython version is 13 times faster than the Python version! What could explain this?
- Multiple things:
In this program, very little computation happen at each line. So the overhead of the python interpreter is very important. It would be very different if you were to do a lot computation at each line. Using NumPy for example.
Data locality. It’s likely that a lot more can fit in CPU cache when using C than when using Python. Because everything in python is an object, and every object is implemented as a dictionary, this is not very cache friendly.
Usually the speedups are between 2x to 1000x. It depends on how much you call the Python interpreter. As always, remember to profile before adding types everywhere. Adding types makes your code less readable, so use them with moderation.
Primes with C++#
With Cython, it is also possible to take advantage of the C++ language, notably, part of the C++ standard library is directly importable from Cython code.
Let’s see what our code becomes when using vector from the C++ standard library.
Note
Vector in C++ is a data structure which implements a list or stack based
on a resizeable C array. It is similar to the Python array
type in the array standard library module.
There is a method reserve available which will avoid copies if you know in advance
how many elements you are going to put in the vector. For more details
see this page from cppreference.
1# distutils: language=c++
2
3import cython
4from cython.cimports.libcpp.vector import vector
5
6def primes(nb_primes: cython.uint):
7 i: cython.int
8 p: vector[cython.int]
9 p.reserve(nb_primes) # allocate memory for 'nb_primes' elements.
10
11 n: cython.int = 2
12 while p.size() < nb_primes: # size() for vectors is similar to len()
13 for i in p:
14 if n % i == 0:
15 break
16 else:
17 p.push_back(n) # push_back is similar to append()
18 n += 1
19
20 # If possible, C values and C++ objects are automatically
21 # converted to Python objects at need.
22 return p # so here, the vector will be copied into a Python list.
Warning
The code provided above / on this page uses an external
native (non-Python) library through a cimport (cython.cimports).
Cython compilation enables this, but there is no support for this from
plain Python. Trying to run this code from Python (without compilation)
will fail when accessing the external library.
This is described in more detail in Calling C functions.
1# distutils: language=c++
2
3
4from libcpp.vector cimport vector
5
6def primes(unsigned int nb_primes):
7 cdef int n, i
8 cdef vector[int] p
9 p.reserve(nb_primes) # allocate memory for 'nb_primes' elements.
10
11 n = 2
12 while p.size() < nb_primes: # size() for vectors is similar to len()
13 for i in p:
14 if n % i == 0:
15 break
16 else:
17 p.push_back(n) # push_back is similar to append()
18 n += 1
19
20 # If possible, C values and C++ objects are automatically
21 # converted to Python objects at need.
22 return p # so here, the vector will be copied into a Python list.
The first line is a compiler directive. It tells Cython to compile your code to C++.
This will enable the use of C++ language features and the C++ standard library.
Note that it isn’t possible to compile Cython code to C++ with pyximport. You
should use a setup.py or a notebook to run this example.
You can see that the API of a vector is similar to the API of a Python list, and can sometimes be used as a drop-in replacement in Cython.
For more details about using C++ with Cython, see Using C++ in Cython.
Language Details#
For more about the Cython language, see Language Basics. To dive right in to using Cython in a numerical computation context, see Typed Memoryviews.